Consider a group lasso problem:
\(min \frac{1}{2N} \|X\beta - y\|_2^2 + \lambda \Sigma_j w_j \|\beta_{(j)}\|_2\), A common choice for weights on groups \(w_j\) is \(\sqrt{p_j}\), where \(p_j\) is number of predictors that belong to the \(j\)th group, to adjust for the group sizes.
If we treat every feature as a single group, group lasso become regular lasso problem.
Derivation:
For group j, we know that
\[0 \in \frac{1}{t}(z_{(j)} - \beta_{(j)} + \lambda w_j \partial\|z_{(j)}\|_2\] \[0 = z_{(j)} - \beta_{(j)} + \lambda t w_j v_{(j)}\]If \(z_{(j)} \neq 0\) \(v_{(j)} = \frac{z_{(j)}}{\|z_{(j)}\|_2}\)
else, any \(\|v_{(j)}\|_2\) such that \(\|v_{(j)}\|_2 \leq 1\) belongs to the subdifferential \(\partial\|z_{(j)}\|_2\)
If \(z_{(j)} \neq 0\), \(0 = z_{(j)} - \beta_{(j)} + \lambda t w_j \frac{z_{(j)}}{\|z_{(j)}\|_2}\)
\(z_{(j)} = (I + diag(\lambda t \frac{w_j}{\|z_{(j)}\|_2}))^{-1} \beta_{(j)} = (1 + \lambda t \frac{w_j}{\|z_{(j)}\|_2})^{-1} \beta_{(j)}\), we can do this becase the element on the diagnoal matrix is all the same
Take norm on both sides, we can get
\[\|z_{(j)}\|_2 = \|\beta_{(j)}\|_2 - \lambda t w_j\]therefore,
\[z_{(j)} = (1 - \frac{\lambda t w_j}{\|\beta_{(j)}\|_2}) \beta_{(j)}\]If \(z_{(j)} = 0\), \(z_{(j)}=0\), at this time, \(\|v_{(j)}\|_2 \leq 1\), i.e, \(\|\beta_{(j)}\|_2 \leq \lambda t w_j\)
therefore, \(z_{j} = (1 - \frac{\lambda t w_j}{\|\beta_{(j)}\|_2})_{+} \beta_{(j)}\)
\[prox_{th}(\beta_{(j)}) = (1 - \frac{\lambda t w_j}{\|\beta_{(j)}\|_2})_{+} \beta_{(j)}\]So our update rule for group laso is:
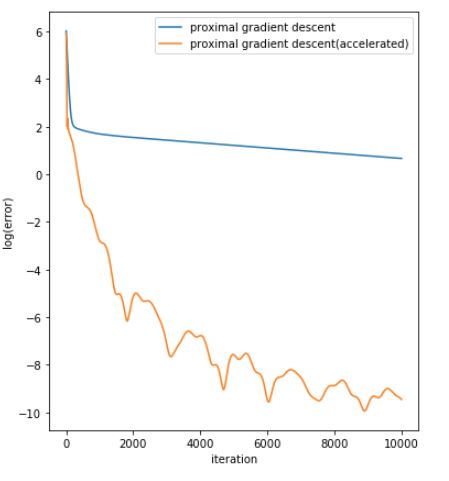
\[\beta_{(j)}^k = prox_{t_kh}(\beta_{(j)}^{k-1} - t_k \nabla g(\beta_{(j)}^{k-1})) = prox_{t_kh}(\beta_{(j)}^{k-1} - \frac{t_k}{N} [(X^{(j)})^T (X\beta^{k-1} - y)])\]We can implement proximal gradient descent as follows, and even with acceleration:
def proximal(beta, lam, t, weight):
coef = max(1 - lam * t * weight / np.linalg.norm(beta, 2), 0)
return coef * beta
def grad_goup(X, y, beta, group):
N = X.shape[0]
return np.dot(X[:, group].T, X@beta - y) / N
def obj(X, y, beta, groups, lam):
N = X.shape[0]
p = X.shape[0]
err_norm = np.linalg.norm(X@beta - y, 2) ** 2 / 2 / N
penalty = 0
n_groups = len(groups)
for i, g in enumerate(groups):
if i != n_groups - 1:
penalty += lam * np.linalg.norm(beta[g], 2) * np.sqrt(len(g))
return err_norm + penalty
def pgd(X, y, groups, epoch, step, lam):
weights = [np.sqrt(len(g)) for g in groups]
beta = np.random.normal(size=X.shape[1])
loss_hist = []
N = X.shape[0]
n_groups = len(groups)
loss_hist = []
while epoch > 0:
err = X@beta - y
for i, g in enumerate(groups):
if i == n_groups - 1:
beta[g] = beta[g] - step / N * np.dot(X[:, g].T, err)
else:
beta[g] = proximal(beta[g] - step / N * np.dot(X[:, g].T, err), lam, step, weights[i])
loss = obj(X, y, beta, groups, lam)
print("loss: ", loss)
loss_hist.append(loss)
epoch -= 1
return np.array(loss_hist), beta
def pgd_accelerated(X, y, groups, epoch, step, lam):
weights = [np.sqrt(len(g)) for g in groups]
beta = np.random.normal(size=X.shape[1])
prev_beta = beta.copy()
loss_hist = []
N = X.shape[0]
n_groups = len(groups)
loss_hist = []
k = 1
while epoch > 0:
v = beta + (k - 2) / (k + 1) * (beta - prev_beta)
next_beta = np.empty(beta.shape)
for i, g in enumerate(groups):
if i == n_groups - 1:
next_beta[g] = v[g] - step * grad_goup(X, y, v, g)
else:
next_beta[g] = proximal(v[g] - step * grad_goup(X, y, v, g), lam, step, weights[i])
loss = obj(X, y, next_beta, groups, lam)
print("loss: ", loss)
loss_hist.append(loss)
prev_beta = beta
beta = next_beta
epoch -= 1
k += 1
return np.array(loss_hist), beta